How SuperAdmins helped “The Charles” design and build a cost-effective DevOps infrastructure capable of taking millions of new unique requests
Case Study Overview
Our Company: SuperAdmins Client Industry: Marketing, Digital marketing Goal: Create cost-effective application infrastructure that can withstand huge load surges (millions of new unique requests) in short periods of time Challenges: Plan out, build and test application infrastructure so it handles heavy traffic loads without any hiccups Services Provided: DevOps, AWS management Campaign Duration: ~ 1 week Results: Powerful and cost-effective infrastructure
Brief
The client got a last-minute project for a marketing campaign that would be presented during a big sporting event. With a potential burst in users during a short period of time, the application needs to be able to handle potentially million unique requests during a short period of time. Apart from this one-time event, the project is planned to be long-lived and promoted during other events in the future.
With roughly one week before the launch date, we needed to plan out the infrastructure, build it and test the performance of the application and infrastructure so that it can sustain the potential heavy load.
The client already had part of the frontend application written so we needed to plan out for the backend application that would be under a lot of stress. The job of the backend API would be to collect some of the user data from the application. Luckily the backend API would be simple enough and the client noted that they could create it in any programming language.
The solution
We all agreed that the best way to go forward in terms of the architecture of the frontend would be an S3 hosted website with a CloudFront distribution in front. This is a standard approach and the client is already familiar with it. Also, we could easily set up a pipeline that would trigger a build process after a commit is made to the production branch in Git. This way we can automate the process of deploying new versions of the frontend application.
The next stage was to define the architecture for the backend application. The first here step was to get insights into what the backend application would be doing and figuring out our options. From a quick brief, the application would be collecting submitted data from the Frontend application and storing it into the database. The initial estimate that the API needs to handle 500k requests within a 15-minute window.
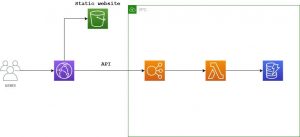
With this information, and given a short period of time to build, configure and test everything – we decided to go with a straightforward solution. AWS Lambda would handle the API requests and the data would be stored in DynamoDB. The proposed infrastructure is shown in the diagram:
Because of the increased traffic that was expected and the fact that we didn’t need most of the API Gateway functionalities, we’ve decided to use the Application Load Balancer (ALB) in front of the Lambda function in order to handle the traffic.
Implementation
The implementation of this architecture is pretty much straight forward. The key components include:
S3 bucket configured as a static website with correct policies
CloudFront distribution configured with two origins. One pointing to S3 bucket for the main domain and the other pointing to the ALB for the /API* path
Application Load Balancer configured with a Lambda function as the target
Lambda function
DynamoDB table
VPC
IAM policies
CloudWatch alarms for Lambda and DynamoDB
After implementing all this, we knew that because of the predicted traffic we would need to increase service limits for Lambda and DynamoDB.
For testing purposes, we would need to simulate a 500k unique POST request to the API and make sure that all the requests are written into the DynamoDB table. In order to do this, we created our own automated scripts and brought up a fleet of EC2 instances that could handle sending this number of requests during a 15-minute period.
The first test was successful. Lambda and DynamoDB were able to handle all the requests during a short period of time. In order to make sure that the infrastructure could take even more traffic we decided to increase the test to 1 million requests within a 15-minute period. During this test, we noticed that some of the requests were not written into DynamoDB and that Lambda was reaching its limits.
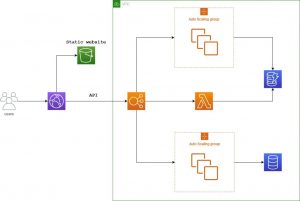
In order to compensate this and make sure that the application would scale, it was decided to introduce new components to the infrastructure. First, we would create an Auto Scaling group with EC2 instances running the same code as the Lambda function and the data would be written also to a DynamoDB but into a different table. There was no issue with the data being written into different tables since all the data would be collected after the campaign and analyzed elsewhere so aggregating the data from multiple sources was an option.
This, however, didn’t resolve a potential bottleneck with DynamoDB. In order to do this, keeping in mind that the data could be aggregated afterwards, we decided to introduce a new Auto Scaling group with the application running on EC2 instances. However, in this case, we decided to store the data into a MySQL database. Because we didn’t expect the MySQL approach to be used much, we didn’t opt in to use Aurora.
All three components, the Lambda function, and the two Auto Scaling groups were configured on the ALB as Target Groups with weight distribution for traffic. This allowed us to distribute the traffic to the Target Groups if necessary.
The final architecture diagram looks like this:
About the Client
The Charles NYC
“The Charles NYC” is a full-service creative agency focused on strategic campaigns, brand storytelling and digital experiences for lifestyle, luxury, finance, media, and technology brands. The Charles NYC team is made up of Strategists, Visual Designers, UX Designers and Developers – enabling them to combine commerce with creativity and big-picture thinking with detailed execution.
Client quote project impression
Josh Currie
Executive Producer – The Charles
Rastko and his team at SuperAdmins are incredibly talented with impressive expertise in infrastructure set up and DevOps. They were able to successfully complete a challenging project with almost impossible turnaround time. Their quick responses and transparent communication style make them a pleasure to work with.
Benefits and results
By making sure that the application can scale and have a fallback mechanism if one of the backend components would fail, we were able to prepare for the high-volume traffic. Also, using Lambda and by keeping the secondary components of the API, the Auto Scaling groups, to a minimum we were able to create a cost-effective infrastructure for the client.